45 שניות
45 שניות. זה הזמן החציוני של אינטראקציה עם Claude Code.
לא 45 דקות. שניות.
רוב השיחות שלנו עם סוכני AI הן קצרות, ממוקדות, ומבוקרות. רק מעל האחוזון ה-99 רואים סשנים ארוכים באמת. זה מספר ראשון שאפשר להפנים מהמאמר האחרון ששוחרר על אוטונומיה של AI AGENTS
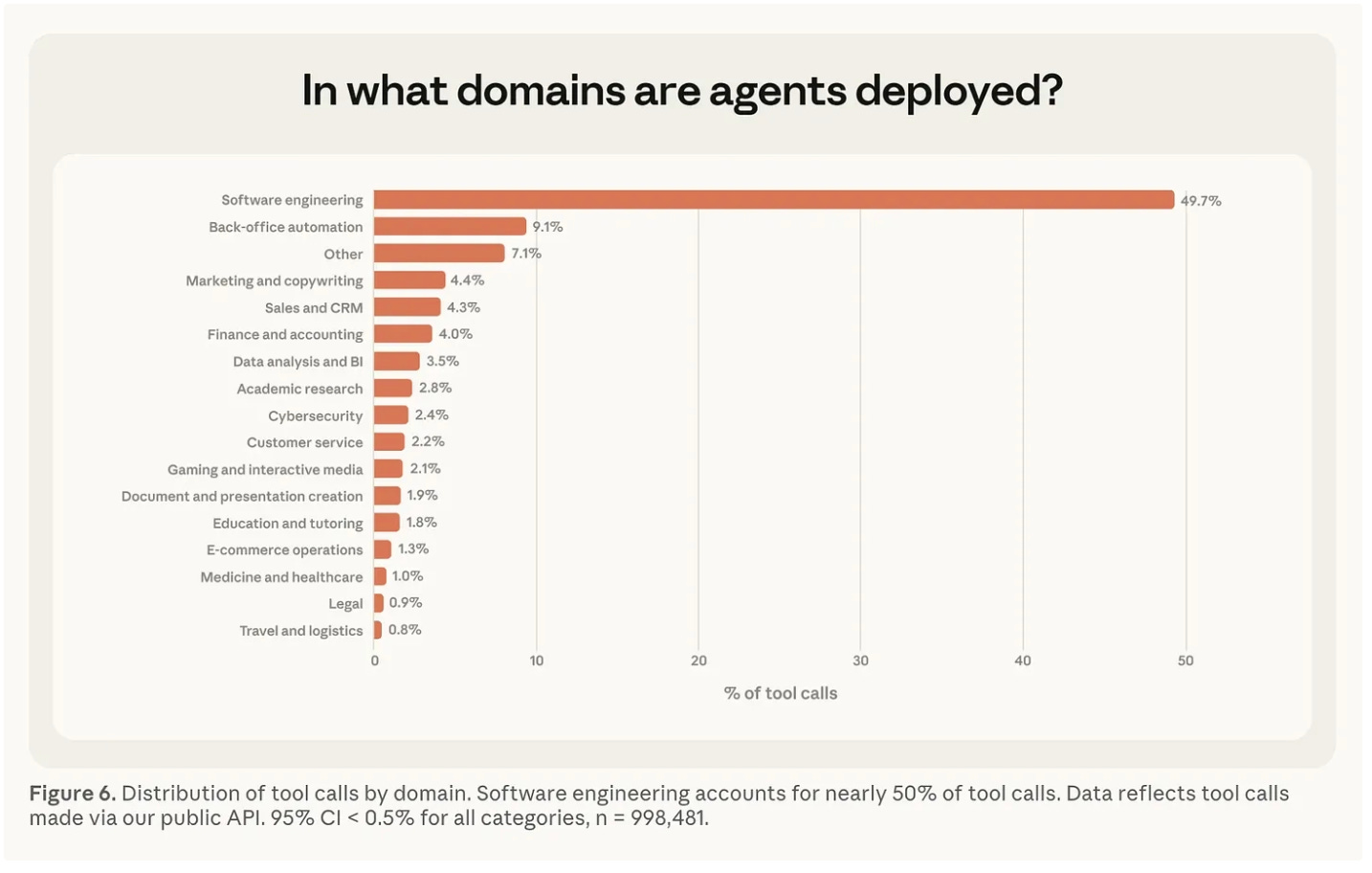
המספר השני: 73% מהפעולות שהסוכן מבצע כוללות פיקוח אנושי. רק 0.8% מהפעולות הן בלתי הפיכות. כלומר – ברוב המוחלט של הזמן, אנחנו עדיין מעורבים. עד לפה הרגשתי שאני בתמונה. עוד נתון מעניין הוא מה השימושים שעושים איתו, וכאן יש מכת מחץ מבחינת קוד, שמהווה כמעט 50% מהניצולת.
מה שמעניין הוא שבין אוגוסט לדצמבר מספר המשתמשים בקלוד קוד לא רק הוכפל, אלא גם הציג שונות מהותית בסוג המשתמשים, ולדעתי כאן המהפיכה האמיתית ואולי השקטה. קלוד קוד הוא מוצר שהצליח לתווך משהו, שאינו יכול להקרא ״וייב קודינג״ , אבל גם אינו מצריך ממך לדעת קוד על בוריו.
מה שמעניין באמת: עקומת הלמידה
משתמשים חדשים מאשרים אוטומטית כ-20% מהפעולות. עם הזמן, האחוז עולה ליותר מ-40%. אבל – וזה הדבר המפתיע – משתמשים מנוסים גם מפסיקים את הסוכן כמעט פי שניים יותר ממתחילים.
זו לא סתירה. זה למעשה בדיוק הדפוס הנכון.
ככל שאתם מבינים יותר מה AI יכול לעשות, אתם גם יודעים טוב יותר מתי להתערב. אוטונומיה אמיתית לא נבנית מבטחון עיוור – היא נבנית מהבנה עמוקה של מתי לתת חופש ומתי לעצור , אבל, קלוד עוצר את עצמו יותר ממה שאנשים עוצרים אותו.
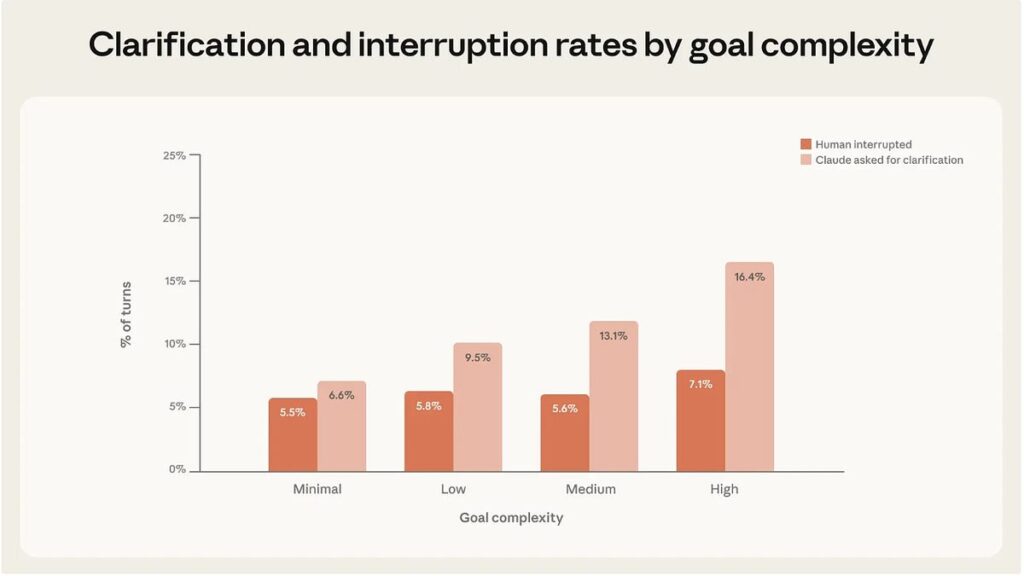
התגלית המפתיעה: ה-AI מפקח על עצמו
והנה הדבר שרוב האנשים לא שמים לב אליו: במשימות מורכבות, Claude עוצר את עצמו יותר ממה שהמשתמש עוצר אותו.
למה הסוכן עוצר? ההתפלגות:
-
35% – מציג אפשרויות למשתמש במקום להחליט לבד
-
21% – אוסף מידע דיאגנוסטי לפני שהוא ממשיך
-
13% – מבקש הבהרה על מה בדיוק רוצים
-
12% – מבקש הרשאות גישה
-
11% – מבקש אישור לפני פעולה רגישה
זה הופך את הנרטיב לגמרי. זה לא רק אנחנו שמפקחים על AI – ה-AI מפקח על עצמו.
אני חושבת שזה אולי אחד הקסמים במוצר הזה, היכולת שלו להטמיע ב UI מה שאני אוהבת לקרוא ״סקר״ – הולידציה מול המשתמש שעוצרת את הקוד כדי לשאול ״ככה את רוצה״? מסייעת בהמון פעמים לשלוט על התוצר, דבר שיחר לנו במוצרים כמו lovable למשל.
אנטרופיק משתמשת במונח חדש שלא הכרתי deployment overhang – האוטונומיה שהמודל מסוגל להתמודד איתה גדולה ממה שהוא בפועל ממש. כלומר – סוכני AI מחזיקים בכוונה יותר ממה שהם משתמשים והמספרים תומכים בזה: שיעור ההצלחה במשימות מורכבות הכפיל את עצמו בין אוגוסט לדצמבר. מספר ההתערבויות האנושיות ירד מ-5.4 ל-3.3 לסשן. הכלים נהיים טובים יותר, ואנחנו צריכים להתערב פחות.
ההמלצה של אנטרופיק למנהלים? תפסיקו לעצב את המיקרו-מנג’מנט. אל תכפו אישור על כל פעולה. תעצבו מערכות שמאפשרות ניטור והתערבות כשצריך. אני מתחילה לחשוב שרוב הסיפור הוא זה, ושזה מה שנור לנו לעשות. כלים ניהוליים לכל הטוב הזה.
שווה לומר שאנטרופיק כן מתייחסת במדידה שלה גם לארגון Metr, שמוביל הערכות של יכולות AI agents, ומודד ביצועים בתנאי מעבדה – בלי אינטראקציה אנושית או השלכות אמיתיות. לטענתה של אנטרופיק המדידה ם מתמקדת בקושי משימה, ולא באוטונומיה בפועל.
בעולם האמיתי, אוטונומיה היא לא תכונה של המודל. היא תוצאה של שיתוף פעולה בין מודל, משתמש ומוצר.
הנתונים מראים את זה ברור: סשנים גדלו מ-25 דקות בספטמבר ליותר מ-45 דקות בינואר. כשגל משתמשים חדשים הצטרף – הממוצע ירד. כש-Opus 4.6 יצא – הוא עלה בחזרה.
השורה התחתונה
הנקודה החשובה פה היא לא כמה חכם המודל. הנקודה היא שהאוטונומיה של AI agents נבנית בהדרגה, דרך אמון הדדי בין האדם לכלי.
וזו בדיוק הגישה הנכונה.
כי אוטונומיה שנבנית על נתונים אמיתיים, עם פיקוח אנושי ושקיפות – היא אוטונומיה שאפשר לסמוך עליה קצת יותר (לי עדיין אין כאלה שרצים לבד בלילה, האחרון שניסה העלים לי סדנא בבוקר שלמחרת ופוטר 🙂
עד כמה לשחרר ומתי – בפוסט הבא על ארכיטקטורה של מידע




